Abstract
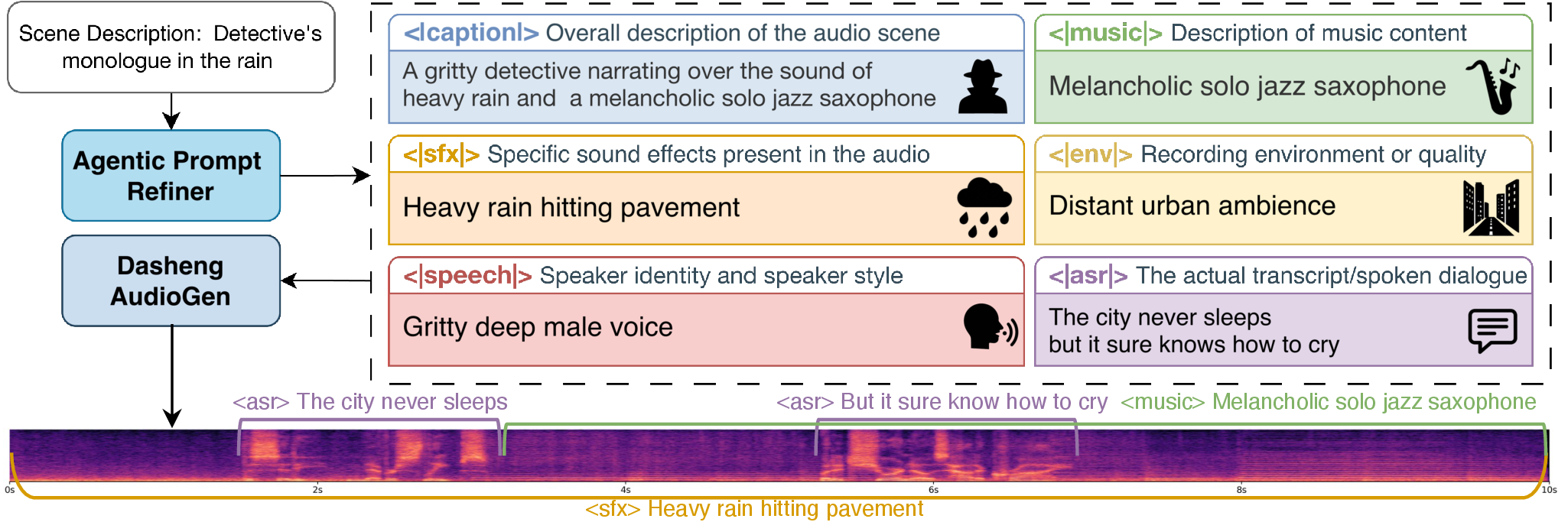
Audio generation has long been fragmented, with speech, music, and sound effects produced by domain-specific models that fail to jointly generate coherent audio scenes from a single description. The key obstacles are insufficient fine-grained supervision for real-world mixed audio and limited acoustic representations for modeling concurrent audio components. We present Dasheng AudioGen, a unified framework for generating general mixed-audio scenes from text. Dasheng AudioGen introduces structured multi-view captions, which explicitly decouple complex acoustic scenes into complementary description views, thereby enabling fine-grained control over audio layers. Furthermore, we employ a high-dimensional unified semantic-acoustic representation as the shared latent space. It injects semantic priors that facilitate cross-modal training convergence, while its high-dimensional feature space provides sufficient capacity to disentangle and fuse concurrent audio components effectively. With these designs, a simple flow-matching DiT achieves high-quality end-to-end audio scene generation. We also establish a comprehensive evaluation pipeline for audio scene generation. Experiments demonstrate that Dasheng AudioGen achieves performance approaching real-world recordings in mixed-audio categories, while remaining competitive with specialized models in single-type generation tasks.